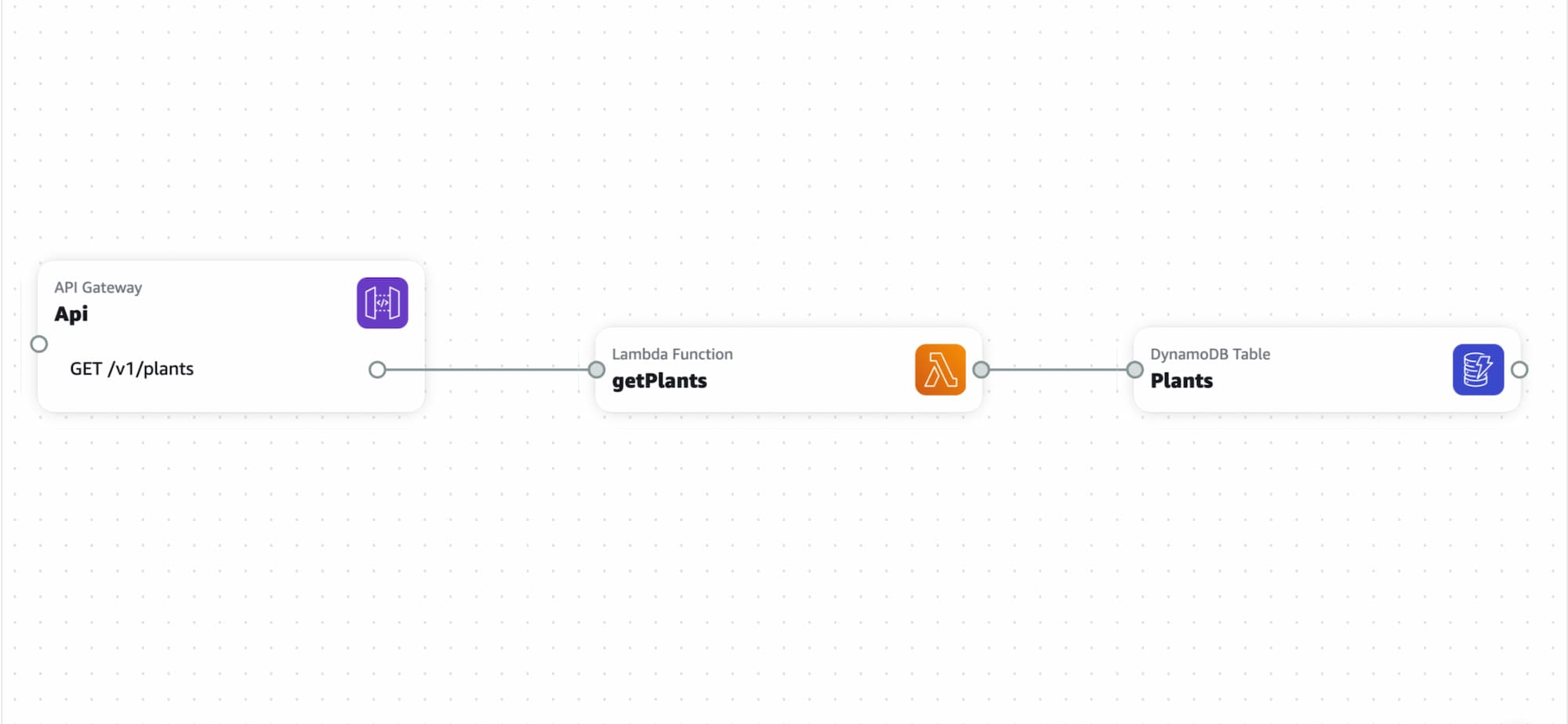
Want to quickly build and deploy an AWS backend? In this post I’ll be spinning up an AWS API Gateway endpoint running a Node.js Lambda Function which connects to a DynamoDB Table. I will use AWS SAM for deployment.
This post is supplemental to another post where an overview of AWS application composer is presented. Please read that first before proceeding here. For the best experience make sure your browser supports the File System Access API.
Bonus: This post will also cover loading some data into a DynamoDB Table and configuration of an API endpoint to pull that data.
Prerequisites
To follow along you will need:
- An AWS account (free tier is fine)
- AWS access keys
- You’ll need to make sure your user has the necessary IAM permissions to interact with the various AWS resources mentioned above. It’s a best practice to attach permissions to an IAM user group and then add your user to that group.
- AWS SAM CLI
- Bonus section: Python, if you’re on macOS you likely already have this available on your system.
Setup in Application Composer
Drag in an API Gateway resource. You can leave all the defaults in place. Click “add route” and select GET for method. The sample dataset I’ll be working with contains information on plants; so I’ll use /v1/plants for the path value. Versioning your API endpoints is a best practice; hence the v1/ prefix.
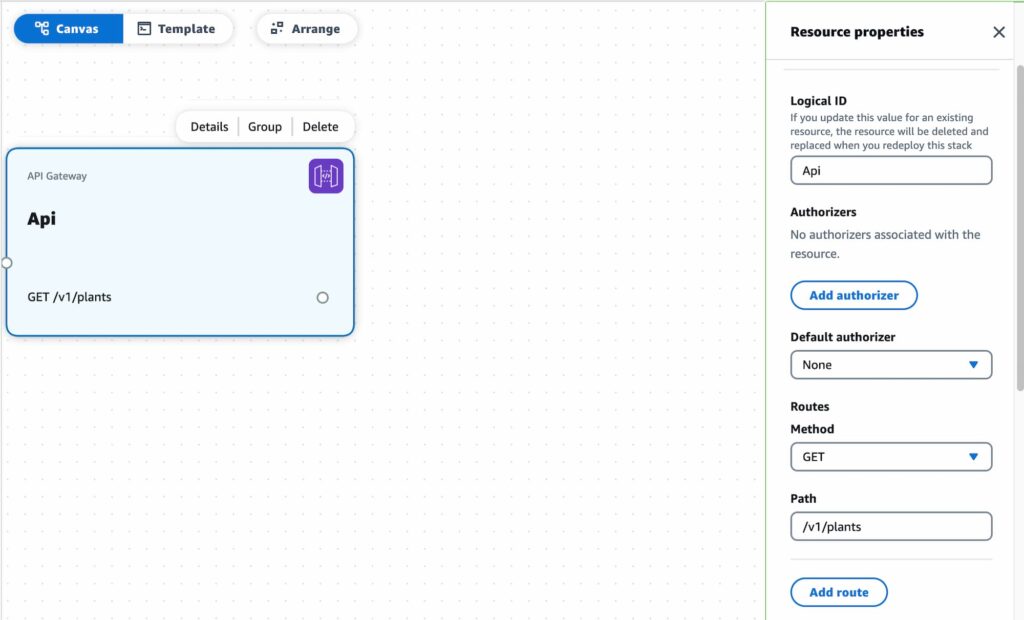
If you intend to call this API endpoint from a browser you’ll want to enable CORS. First you’ll need to add an origin under CORS allowed origins. If your app has multiple domains or you’re developing locally you can use a wildcard value *. Don’t worry this doesn’t mean that you will actually allow any origin to use your API, your endpoint can be configured to set CORS response headers. CORS allowed headers should also be set per your applications’ needs.
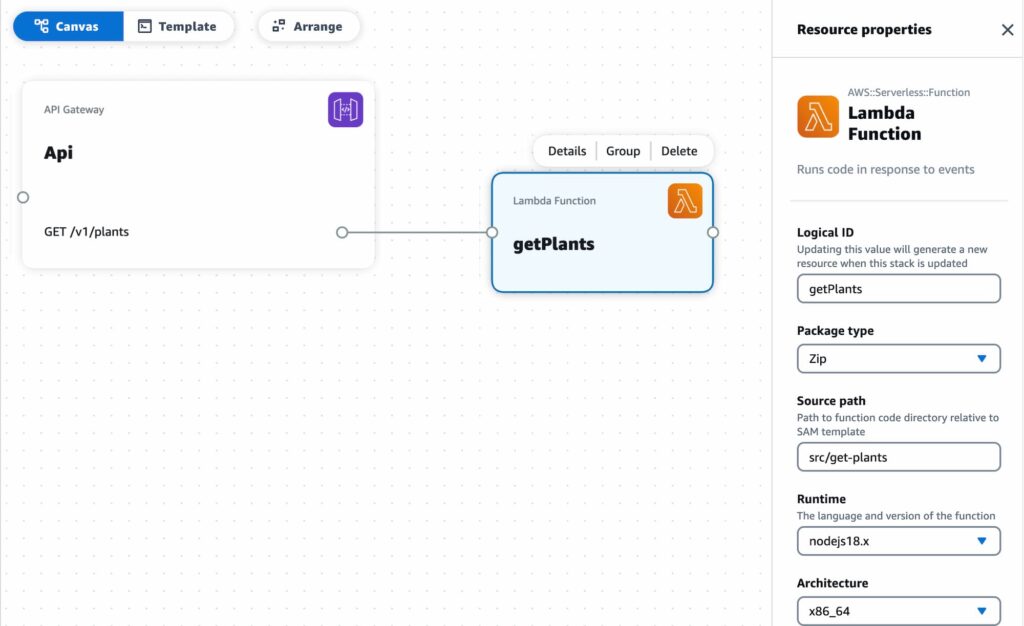
Next drag in a Lambda Function resource. The two things to edit here are Logical ID and Source path. The former is an identifier for the resource and the latter will dictate where in your projects file system the endpoint code will reside.
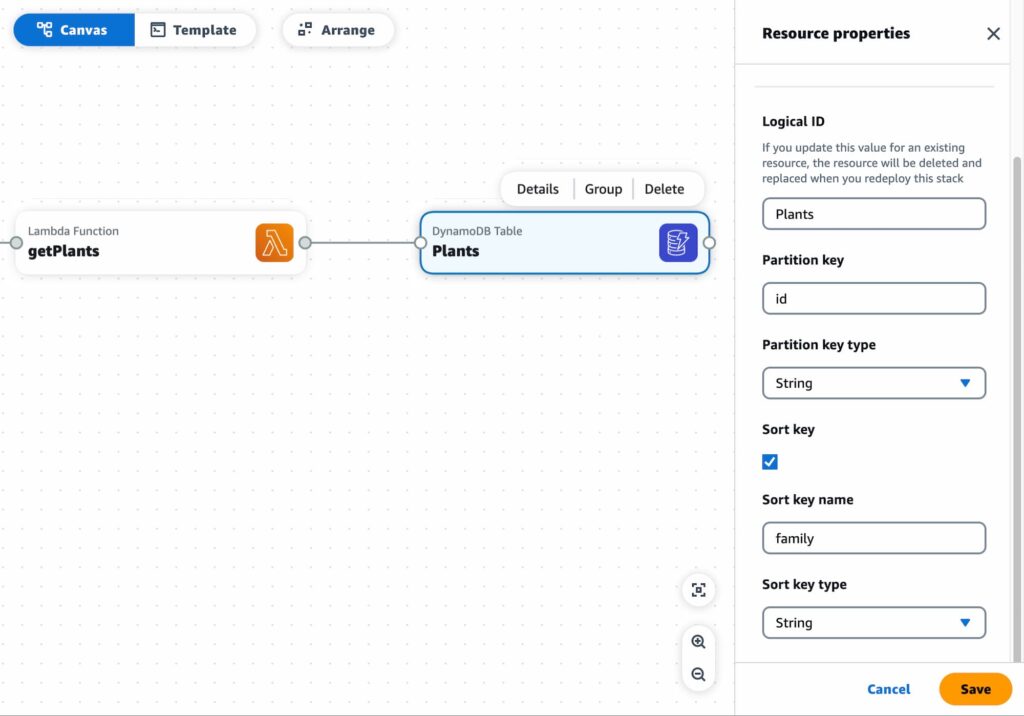
Finally add in a DynamoDB Table resource, name it and set the field name for the partition key. Using a sort key is a good idea. With this in place we are ready to deploy our AWS backend.
Deployment
First thing needed here is to create an S3 bucket where SAM will upload an AWS CloudFormation template. To avoid confusion make sure you are being consistent with your region selections. Leave all defaults as is when creating your bucket.
Time to run some commands. The following is lifted from this stack overflow answer, but I’ll provide additional context here / link up documentation for your reference. In your command line change directory into your project where the template.yaml file is. First up run sam build which will handle project dependencies and prepare source code for deployment.
sam build sam package is next, replace YOUR_BUCKET_NAME_HERE with the name of the S3 bucket you created.
sam package --s3-bucket YOUR_BUCKET_NAME_HERE --output-template-file packaged.yaml Finally sam deploy. Replace YOUR_REGION with the region you’ve been using. Replace YOUR_STACK_NAME with a name of your choosing. SAM will use that name for the AWS CloudFormation stack it generates.
sam deploy --template-file packaged.yaml --region YOUR_REGION --capabilities CAPABILITY_IAM --stack-name YOUR_STACK_NAMEThe output of the above command will show changes to your AWS CloudFormation stack. If all went well you’ll see such a success message:
Successfully created/updated stack - YOUR_STACK_NAME in YOUR_REGIONAt this point your AWS backend is deployed! Head over to the API Gateway console to find your new endpoint. DynamoDB will now have your table as well. Make sure to check the correct region is selected in your AWS console.
Populate DB with data
There are a number of ways to go about populating your DB. I’ll keep things simple and use a .csv file as my datasource. For reference here is the sample data I’m working with.
To upload this data I’ll use boto3, the AWS SDK for Python. You could install boto3 as noted in that readme; however, if you’re committing code to a repository it’s better to use a requirements file.
The upload script I’m using is taken from Kevin Wang’s CSV To DynamoDB post. Depending on your setup you may run into such error:
UnicodeDecodeError: 'charmap' codec can't decode byte 0x81 in position 3463: character maps to <undefined>To get around this you’ll need to add an encoding parameter to the open function:
csvfile = open(filename,encoding='utf-8')Given my sample data my batch.put_item looks as follows:
batch.put_item(
Item={
'id': row['id'],
'common_name': row['common_name'],
'scientific_name': row['scientific_name'],
'family': row['family'],
'description': row['description']
}
)I’ve named my file dynamo_upload_plants.py and saved it at the root my project. To upload I run this command:
python3 dynamo_upload_plants.pyIf all goes well you’ll see “done” in your command line output. Head over to your DynamoDB Table and behold your data!
Retrieve data
Several options exist for retrieving data from dynamoDB. If your intent is to search a database your two main options are Query and Scan. Either is fine for small to medium tables; however for larger tables Query is likely the way to go as the lookup is more efficient. Scan will return everything before applying filtering.
Further efficiency in querying large tables can be gained by running queries against a Global Secondary Index. Some things worth noting when setting up an index:
- Indexes increase storage costs – try to include only a minimal subset of your data.
- Many indexes equals more writes that dynamo has to account for when the base table is updated yielding more costs.
- If your base table is regularly updated be mindful of failure edge cases. In these scenarios table changes may take longer to propagate to the indexes.
For my use case I’ve set up an index which contains columns family and common_name. My API endpoint will accept a family query parameter and return the ID’s and Common Names for matches within a family. Here is a working example of that:
import { DynamoDBClient } from "@aws-sdk/client-dynamodb";
import { DynamoDBDocumentClient, QueryCommand } from "@aws-sdk/lib-dynamodb";
function buildSuccessResponse(payload = {}) {
return { statusCode: 200, body: JSON.stringify(payload) };
}
export const handler = async function (event) {
const family = event.queryStringParameters?.family;
const promise = new Promise((resolve, reject) => {
if (!family) {
const r = buildSuccessResponse({ Count: 0, Items: [] });
return resolve(r);
}
const client = new DynamoDBClient({ region: process.env.AWS_REGION });
const ddbDocClient = DynamoDBDocumentClient.from(client);
const params = {
TableName: process.env.TABLE_NAME,
IndexName: "family-common_name-index",
ExpressionAttributeNames: { "#family": "family" },
ExpressionAttributeValues: { ":family": family },
KeyConditionExpression: "#family = :family",
ProjectionExpression: "id, common_name"
};
const command = new QueryCommand(params);
ddbDocClient
.send(command)
.then((response) => {
const r = buildSuccessResponse(response);
resolve(r);
})
.catch((e) => {
reject(Error(e));
});
});
return promise;
};
This lambda code is written as an ES module. To use this syntax I updated my /src/get-plants/package.json file as follows:
{
"name": "function",
"version": "1.0.0",
"type": "module"
}
Our up and running AWS backend is now ready to connect to a front end. The URL to call your endpoint can be found in your Amazon API Gateway console. Navigate to your API and you’ll find the invoke URL under Stages. You can then append your endpoints to that invoke URL. In my case my endpoint location looks like this:
https://API_ID.execute-api.MY_REGION.amazonaws.com/Prod/v1/plants?family=Apiaceae